AUTHOREA
Log in
Sign Up
Browse Preprints
LOG IN
SIGN UP
Sim Superville
MSc student at Imperial College London
Studying Applied Biosciences and Biotechnology
london
Public Documents
1
January 20, 2020
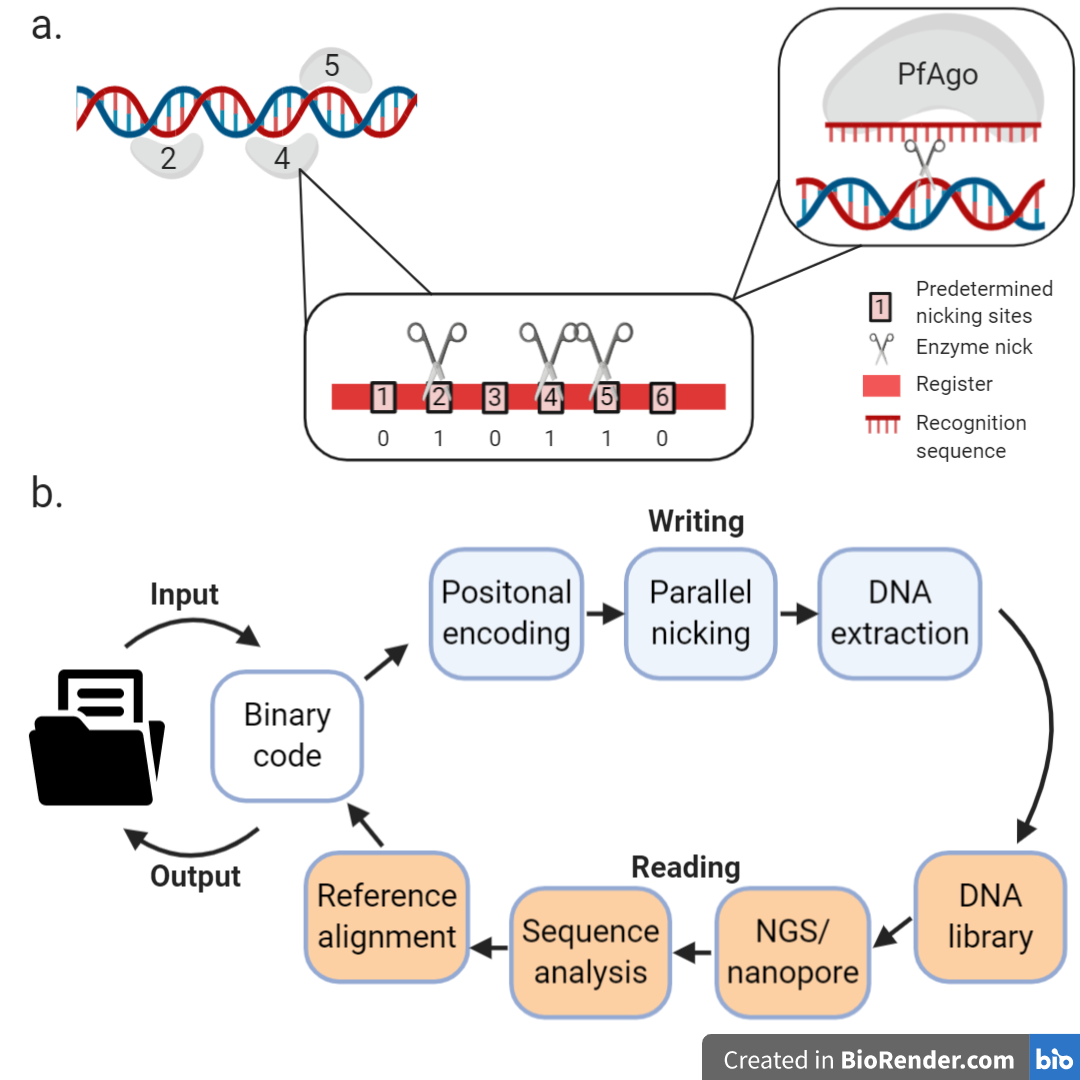
Storing data in the backbone of DNA
Sim Superville