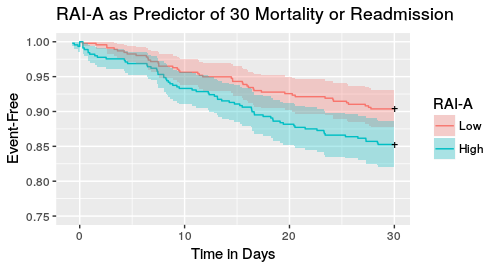
Significance[safety-net hospitals are doubly-disadvantaged... first, because the risk adustments currently in use do reflect all relevant information about risk that is available pre-operatively, and even these metrics fail to model socioeconomic disparities. Secondly, safety-net hospitals have limited resources that ought to be used for for patient care rather than hiring armies coders or purchasing expensive proprietary business intelligence services. We will fill the risk adjustment gap by building on lessons learned from our work with PCORNet and CTSA to develop risk adjustment methods that do not ignore ethnic and socioeconomic disparities and compare them on a level playing field against currently used methods. We will fill the resource gap that limits the ability of health systems that serve disadvantaged populations to fully utilize data available to them by narrowing down the variables available in EMR systems to a parsimonious set that is at greatest risk of being under-reported along with an open-source tool-chain for extracting these variables.]Innovation[our models will be more granular than what exists? maybe finding a better tradeoff between the entire patient history versus only the last X months... borrowing from the world of finance where time series have damping functions... of course, shiny open-source tools for other sites to use freely...]ApproachAimsAim 1Aim 2Data SourcesWe have access to identified local copies of surgical registry data submitted by STVHS to the VA Surgical Quality Improvement Program (VASQIP) \cite{daley_validating_1997} and by UHS to the American College of Surgeons National Surgical Quality Improvement Program (ACS NSQIP) \cite{bilimoria_development_2013}. These sources, to which we will collectively refer as SQIP, provide information about patient demographics, comorbidities, functional status, whether or not the patient is community-dwelling, 30-day mortality, and 30-day re-admission. In total, our data spans the years 201X to 2016 and includes XX,XXX surgeries -- XX,XXX from VASQIP and XX,XXX from ACS NSQIP. The demographic characteristics of these patients are shown in [table 1]. We also have access to database extracts from the billing systems and the electronic medical record systems (EMR) of STVHS, UHS, and our faculty outpatient practices (UT Medicine). In addition we have access to several public data sources that will be described below.Data Linking and ExtractionWhere possible, EMR data will be extracted from our i2b2 data warehouse \cite{murphy_instrumenting_2009} using a novel data extraction tool we developed \cite{bokov_denormalize_2016} as part of our work with PCORNetas part of our work with PCORNet and leveraging the data standardization, de-identification, and verification of HERON, an open-source extract-transform-load framework \cite{waitman_expressing_2011} to whose development we contributed as members of the Greater Plains Collaborative \cite{waitman_greater_2014}. Data that is not migrated from the EMR to i2b2 or is external to the EMR will be extracted by our experience clinical informatics team directly from the respective raw extracts.We will use patient and visit record numbers to link SQIP data with medical histories from their respective EMRs, which will allow us to de-duplicate patients as well as obtain data on mortality and adverse events beyond the 30-day window of SQIP. This will also give us the opportunity to cross-check SQIP and fill in any missing data. We have matched all patient addresses in the UHS system to census block groups and by the start of the funding period will have done so for all STVHS surgery patients. This cross-walk from patients to census block groups enables us to associate each patient with the median household income from the 2013 American Community Survey [ref] corresponding to their race and Hispanic/non-Hispanic indicator. From our previous experience with secondary use of EMR systems for research we have found that vital status documentation is often incomplete. For this reason we will supplement the vital status with dates of death from the Social Security Death Master File matched to patients by name, SSN, date of birth, and zip code of last residence.For the second aim, we will use billing records for surgeries represented in ACS NSAQP from UHS to obtain reimbursement amounts and DRG codes used for those reimbursements. We will collate SQIP data with visits in the EMRs of the three healthcare systems (STVHS, UHS, and UT Medicine) to produce unified histories of diagnoses, labs, and procedures for each of the patients from SQIP. We will process the procedure and diagnosis codes from these enriched histories with MS-DRG Grouper software \cite{center_for_medicare_and_medicaid_service_medicare_2016} to calculate the DRGs that would have been coded had the respective health systems had access to more complete information and the resources to extract it.AnalysisWe will calculate the surgical administrative risk assessment index (RAI-A) for patient records in the VASQIP \cite{hall_development_2017} and NSQIP \cite{isharwal_preoperative_2017,melin_preoperative_2015} registries of STVHS and UHS, respectively. This RAI-A score will be used as the predictor to fit Cox proportional hazard models \cite{cox_regression_1972} for time from surgery until first unplanned re-admission and until mortality. We will update these models with the following additional variables: race, gender, Hispanic/Latino ethnicity, and median household income and use bi-directional stepwise regression \cite{venables_modern_2002} to find a parsimonious set of demographic covariates that significantly improve predictive accuracy. Separate randomly selected subsets of the eligible patients will be used for model development and model validation.[Here I plan to describe comparing the predictive power of the risk adjustments actually used for MACRA against the base RAI-A score and against the RAI-A + social/demographic info. A significant difference in the first comparison is evidence that the current risk adjustment does not go far enough. A significant difference between base RAI-A and RAI-A + social/demographic info means that the additional social/demographic factors are important and are not captured by RAI-A alone. I'm not sure exactly how I will phrase this yet and I need to read further into the papers you sent until I know what I'm talking about regarding risk adjustments that are currently used.]For the second aim, we will rank the data sources and individual codes by their impact on health-system reimbursement. We will also rank diagnosis and procedure codes by the degree to which their omission correlates with race, ethnicity, or income.Sample Size and Power AnalysisA recent retrospective study \cite{segal_development_2017} was able to detect significant differences in outcomes that included death and hospitalization in records from only 5888 patients that consisted solely of diagnosis and procedure codes from at most two 6-month windows per patient. We have over Xx that sample size, continuous visit histories going back to four years or more, and a richer dataset (as described above). [could use help from Chen-Pin with a good way to do power analysis for this experimental design, particularly aim 2].Expected Outcomes[placeholder]Potential Problems and Alternative Approaches[placeholder]Timeline[placeholder]Dissemination of Software and Data[Not sure what we can say about de-identified data]. It is the standard practice of our informatics group to release all source code [ref: survomatic, datafinisher, and chinotype citations once I have DOIs for the latter two] that is free of PHI or proprietary material under the GPL v2.1 open source license and post it on a public repository such as GitHub or BitBucket. Through our participation in ACT, PCORNet, and UT-HIP we are part of very active open source developer communities that are likely to benefit from and contribute further improvements to software that we disseminate in this manner.Human Subject Protection[placeholder]