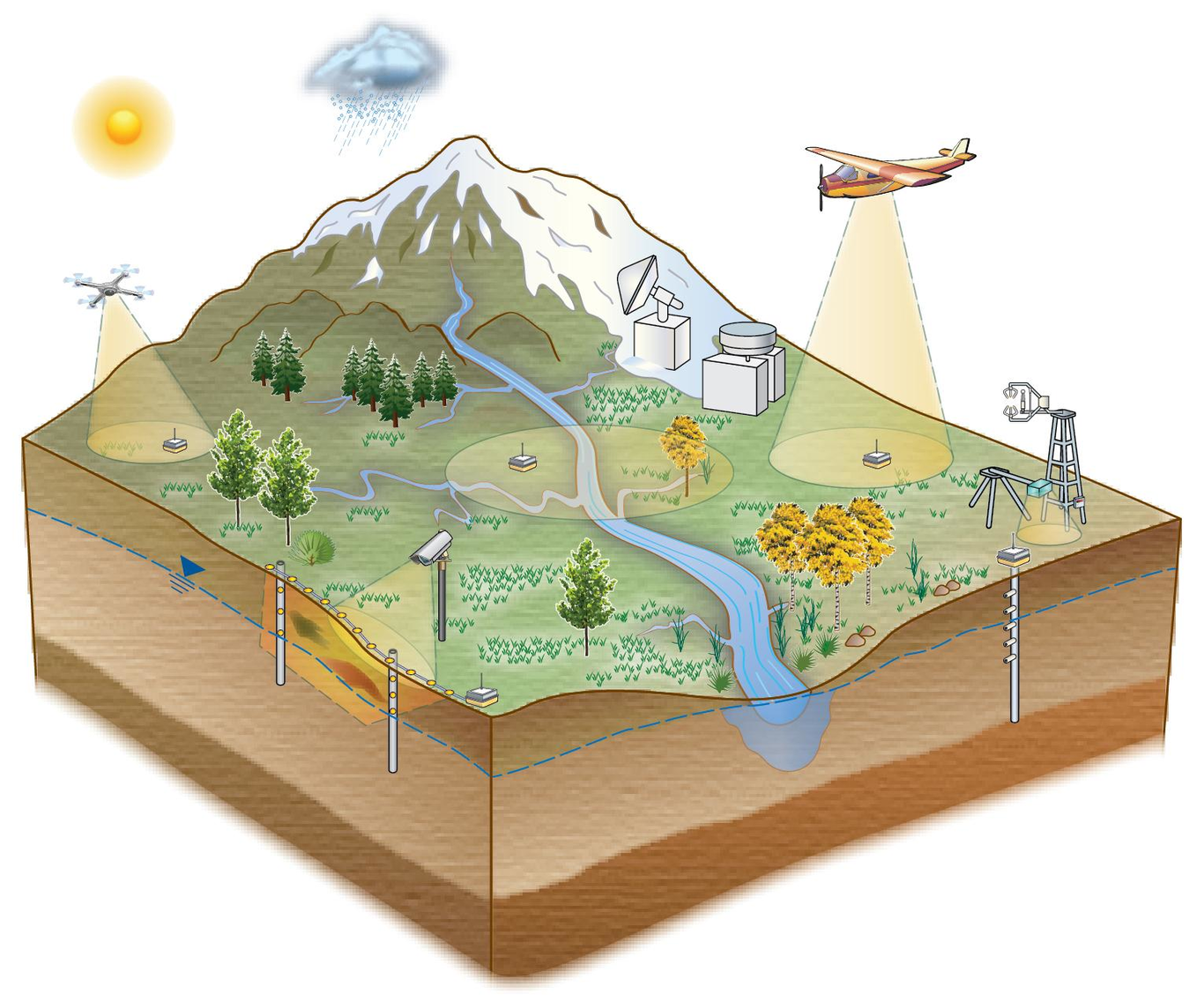
Diverse, complex data are a significant component of Earth Science’s “big data” challenge. Some earth science data, like remote sensing observations, are well understood, are uniformly structured, and have well-developed standards that are adopted broadly within the scientific community. Unfortunately, for other types of Earth Science data, like ecological, geochemical and hydrological observations, few standards exist and their adoption is limited. The synthesis challenge is compounded in interdisciplinary projects in which many disciplines, each with their own cultures, must synthesize data to solve cutting edge research questions. Data synthesis for research analysis is a common, resource intensive bottleneck in data management workflows. We have faced this challenge in several U.S. Department of Energy research projects in which data synthesis is essential to addressing the science. These projects include AmeriFlux, Next Generation Ecosystem Experiment (NGEE) - Tropics, Watershed Function Science Focus Area, Environmental Systems Science Data Infrastructure for a Virtual Ecosystem (ESS-DIVE), and a DOE Early Career project using data-driven approaches to predict water quality. In these projects, we have taken a range of approaches to support (meta)data synthesis. At one end of the spectrum, data providers apply well-defined standards or reporting formats before sharing their data, and at the other, data users apply standards after data acquisition. As these projects continue to evolve, we have gained insights from these experiences, including advantages and disadvantages, how project history and resources led to choice of approach, and enabled data harmonization. In this talk, we discuss the pros and cons of the various approaches, and also present flexible applications of standards to support diverse needs when dealing with complex data.